
You f***ed up a long time ago!
A question about code reviews on my company’s intranet recently piqued my interest:
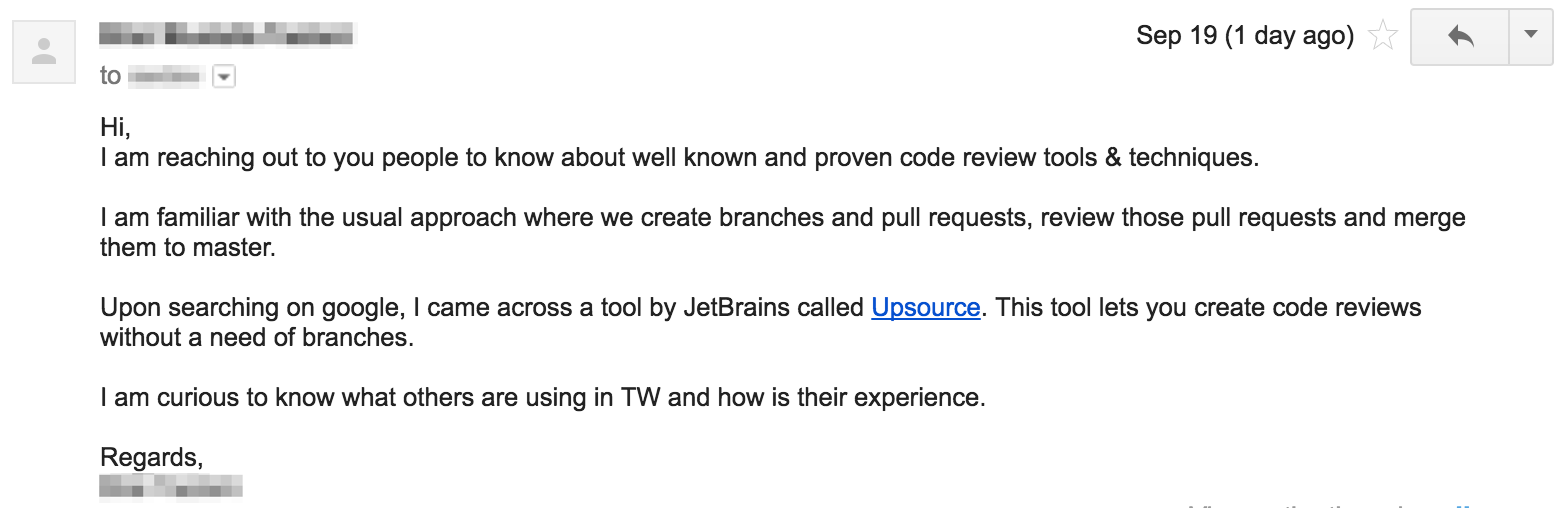
Someone asked the obvious question: what are you trying to achieve? and the original poster responded:
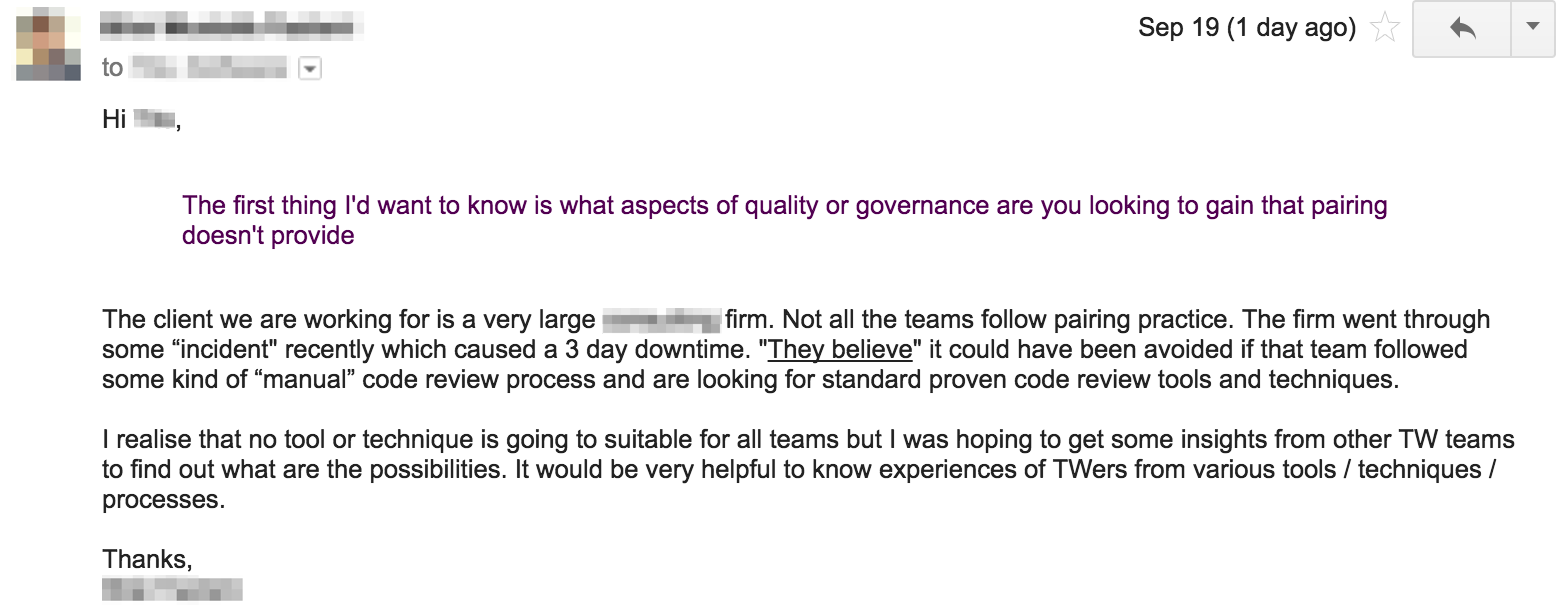
At this point I was intrigued. My Spidey sense was tingling, telling me there were deeper problems here that wouldn’t be solved by just a code review tool. To confirm, I started with some simple questions:
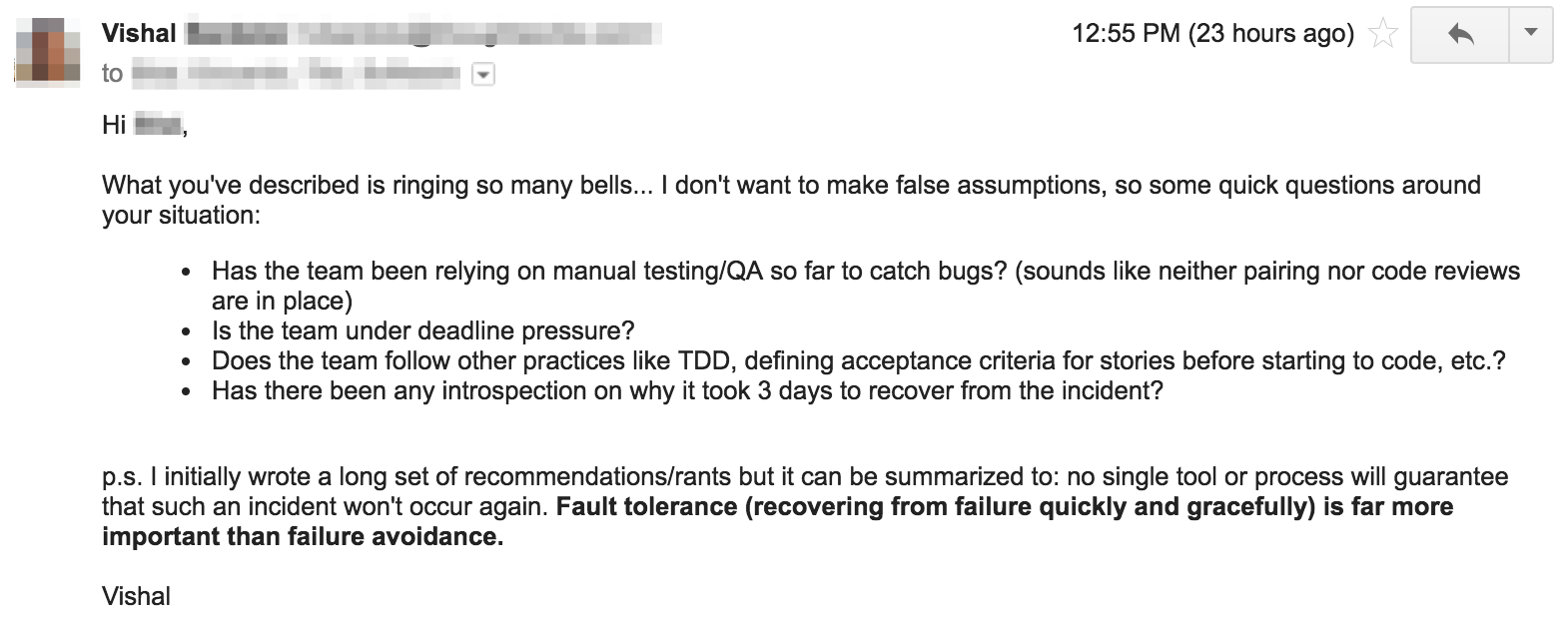
Here was the reply:

So to summarize: a large client had a major 3-day outage. They believe that a manual code review would have caught the error; and have thus mandated that all dev teams across the organization need to do manual code reviews from now on. And they asked us to put tools and processes in place to enforce this.
What would you do?
It’s at times like this that I like to quote Kurt Osiander:

This is Kurt Osiander. He is a Jiu Jitsu black belt and coach, very popular in the BJJ community for his profanity-laden Move of the Week training videos. One particular video has become legendary. Someone had emailed Kurt asking how to get out of a particularly bad position. His response:
You fucked up a long time ago. It’s so bad that now you’re gonna have to work really hard.
In other words, if a minor bug caused a 3-day system outage, you have much deeper problems that code reviews aren’t going to solve.
Clients often don’t like to hear that. Nobody likes deep, introspective, long-term cultural changes that sound painful even if it solves a bunch of underlying problems. At some level everyone prefers the quick fix. And yet… this is a test of your consulting skills. Can you convince them to do what they need, not what they want?
So what follows is an imaginary conversation with the client in this situation.
Why do you want to have a standard code review process across all teams? Is it so that:
- such an outage never happens again, or
- if it does happen, we can recover in a much shorter period of time with minimal impact to the business
Here’s the bad news: no tool or process can guarantee that such an incident won’t occur again. There’s a saying in security circles, “Worry less about stopping the blast and more about controlling the blast radius.” That applies here. Outages will happen - people are human after all. What matters is how quickly and painlessly you can recover.
Fault tolerance (recovering from failure quickly and gracefully) is far more important than failure avoidance. As my friend Yogi Aradhye likes to say:

We understand that outages are painful. So in the short term, there are a few things we can do to prevent more outages.
Immediate steps:
In the short term, prevention will help. Let us introduce code reviews in the following way:
1) Choose a review tool familiar to everyone
The specific tool used for code reviews doesn’t matter beyond a point, so stop searching for a silver bullet. If everyone knows how pull requests (PR) are created/reviewed/merged on Github, that’s good enough to start with.
2) Start with a small number of PR reviewers
Their first priority is to set and enforce good development practices in their teams. They will be a bottleneck initially… and that’s okay. The goal right now is not speed, it’s for the team to get used to a higher standard. As the new standards are picked up, the pool of reviewers can be increased until everyone on the team is reviewing PRs.
One crucial detail: the “standards” should be publicly documented and open to updates. One team I was on held twice-a-week meetings where we asked questions about the standards, updated them as needed, etc. This is crucial to building shared understanding and ownership.
3) Add acceptance criteria to all stories
A user story must have acceptance criteria before development can start - and part of the code review should include the check “did you satisfy all the acceptance criteria?”
4) Use MoSCoW-style prioritization when providing feedback
e.g. “Must: add tests for this new functionality” or “Should: extract method here” or “Could: rename variable x to invoiceTotal.”
This is really useful because it helps developers prioritize the PR feedback. Sometimes there just isn’t time to tackle all the feedback; a good compromise is to fix all the Must-haves and put the Should/Could items on a tech debt backlog.
Long term steps:
Hopefully you understand by now, this incident is a symptom of larger problem. If the attitude so far has been like Jack Bauer’s here:

… then they probably haven’t had time for other good things like TDD, acceptance criteria, CI, CD etc. You need a deeper cultural change that values such good practices. Not only do they prevent incidents; they make triage and recovery much easier.
Slow Down and Invest
Slow down to invest in practices that will make incidents less likely, and their impact more manageable:
- Pay down tech debt as a part of each Sprint
- Use best practices like TDD. Introduce your team to the test pyramid.
- Invest in automation: CI, CD pipelines, infrastructure as code, will all make recovery so much quicker
- Maybe simply allow more time for manual testing, both for devs and QAs
Build Quality In
This is one of the principles of Lean Development: build quality in. To quote Dr. Deming:

The #1 thing you can do for this is to involve QA throughout the development process. From writing good acceptance criteria, to knowing what unit tests, to doing frequent desk checks, a good QA team can be your developer’s best allies in making a quality product. Unfortunately in most dev shops, QA is treated like a second-class citizen. If you can make the cultural transition to where your developers partner with QAs, and feel accountable to them, the benefits will be enormous.
Build a Culture of Accountability
I have written before about making the code review an accountability conversation. This is critical to making the entire endeavor a success.
Summary
It’s never easy or popular to take the long-term view on things. But as leaders, as consultants in charge of critical missions, it’s what we must do to bring about real improvements.